


 In der heutigen Geschäftswelt ist künstliche Intelligenz (KI) nicht mehr nur ein Zukunftstrend, sondern eine entscheidende Technologie, die Unternehmen dabei hilft, ihre Prozesse zu optimieren und Wettbewerbsvorteile zu erzielen.
In der heutigen Geschäftswelt ist künstliche Intelligenz (KI) nicht mehr nur ein Zukunftstrend, sondern eine entscheidende Technologie, die Unternehmen dabei hilft, ihre Prozesse zu optimieren und Wettbewerbsvorteile zu erzielen.
Das stellt die Entscheider bei Systemhäusern, Managed Service Providern und anderen Anbietern von IT Infrastruktur vor die Herausforderung, Hardware Konzepte zu identifizieren, die den unterschiedlichen Anwendungsszenarien bei KI Projekten gewachsen sind.
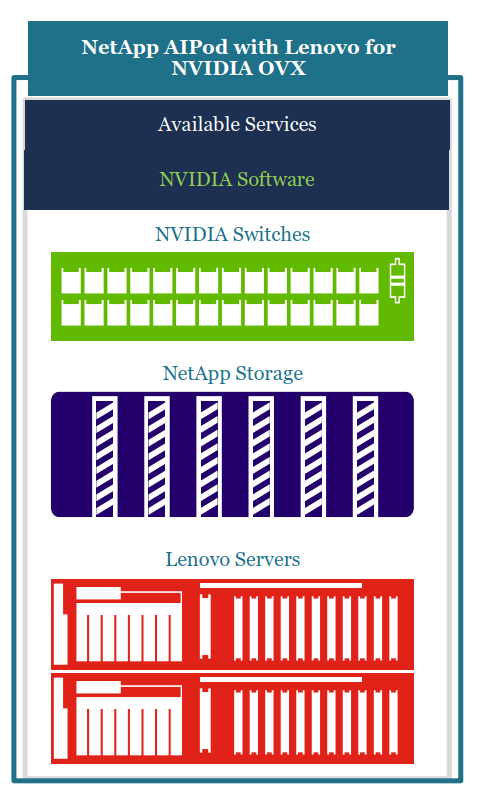
Der NetApp AIPod with Lenovo for NVIDIA OVX ist ein klassisches Beispiel wie verschiedene Hersteller partnerschaftlich zusammenarbeiten, um eine optimierte Lösung für Ihre Kundenumgebungen zu finden. Die gezielte Zusammenführung geeigneter, leistungsfähiger Komponenten zu einem Solution-Stack erlaubt es dabei stets, die notwendigen Anpassungen für das reale Kundenszenario vorzunehmen. Der Schwerpunkt dieses Lösungsstacks liegt auf dem Use Case RAG und Inferencing, sowie dem Fine Tuning – bei den grösseren Lösungen.
Lenovo liefert leistungsstarke, zertifizierte Serversysteme, die von der Systemarchitektur darauf ausgelegt sind, mehrere GPU Adapterkarten optimal nutzen zu können. Die GPU Adapterkarten stammen aus dem Hause NVIDIA, ebenso wie die Netzwerkinfrastruktur. Der Gesamtaufbau entspricht den Anforderungen die NVIDIA in seinem OVX Systemdesign definiert hat. Dies bildet die Grundlage zur Beschleunigung von Rechenintensiven AI-/KI-Workloads. Leistungsstarke und skalierbare Speichersysteme Flash-Speichersysteme von NetApp runden diesen Lösungsstack ab.
Dabei kann nicht nur ein hoher Datendurchsatz für Data-Lake Anwendungen für das Training und Fine Tuning gewährleistet werden, sondern auch die gesicherte Bereitstellung von Daten sicherstellen für nachgelagerte RAG-/Inverencing Anwendungen. Ausreichende Skalierbarkeit der Speichersysteme stellt sicher, dass sie auch hier mit ihren Bedürfnissen wachsen können.
Die neuesten Modelle der AFF A-/C-Serie können dabei auch direkt mit 200GETH angesprochen werden, was ggf. dabei helfen kann den North-/South-Traffic direkt über die Zentralen Switches laufen zu lassen.
Damit stehen ihnen eine Vielzahl von Anwendungsfeldern offen. Egal ob Handel, Gesundheitswesen, Finanzdienstleistungen oder in Fertigungsgewerben, mit diesem Lösungsstack profitieren sie von einer vereinfachten und validierten Bereitstellung von AI-Technologien für jeden Anwendungszweck.
Vorteile des NetApp AI-Pods:
Der NetApp AI-Pod ist die ideale Plattform für Unternehmen, die das Potenzial der künstlichen Intelligenz voll ausschöpfen möchten.
| Zentrale Komponenten | Größe S | Größe M | Größe L |
| Lenovo SR675 V3 OVX Node | 2 | 4 | 8 |
| NVIDIA L40s GPU | 8 | 16 | 32 |
| NVIDIA Networking Switch | SN3700 | SN4600 | SN5600 |
| 3Yr-NVAIE Lizenz | 8 | 16 | 32 |
| NetApp Storage | AFF C30HA | AFF C60HA | AFF C80HA |
| Anwendung | Edge, Inference, RAG | Inference, RAG, Fine Tuning | Inference, RAG, Fine Tuning |
| Preisdimension | Ca. 345.000 € | Ca. 740.000 € | Ca. 1.870.000 € |

RAG steht für Retrieval-Augmented Generation. Es ist eine Technik, die in IT-KI-Projekten verwendet wird, um die Fähigkeiten von vortrainierten Sprachmodellen zu erweitern. Dabei wird das Sprachmodell mit externen Wissensquellen kombiniert, um genauere und relevantere Antworten zu generieren
Durch die Integration von RAG können KI-Systeme nicht nur auf ihre vortrainierten Daten zugreifen, sondern auch zusätzliche Informationen aus externen Datenbanken oder Dokumenten abrufen. Dies verbessert die Qualität und Genauigkeit der generierten Inhalte erheblich.
Ein klassischer Anwendungsfall hierfür ist etwa die Erweiterung eines Chatbots um dediziertes Spezialwissen. Etwa für den Kunden Support.
Inference bezieht sich in IT-KI-Projekten auf den Prozess, bei dem ein vortrainiertes KI-Modell verwendet wird, um Vorhersagen oder Schlussfolgerungen aus neuen, unbekannten Daten zu ziehen
Nachdem das Modell mit umfangreichen Datensätzen trainiert wurde, kann es Muster erkennen und auf Basis dieser Muster Entscheidungen treffen oder Informationen ableiten.
Dieser Prozess ist entscheidend für viele Echtzeit-KI-Anwendungen, da er es ermöglicht, die erlernten Fähigkeiten des Modells auf neue Situationen anzuwenden.
Fine-Tuning ist der Prozess, bei dem ein vortrainiertes KI-Modell an spezifische Aufgaben oder Anwendungsfälle angepasst wird anstatt ein Modell von Grund auf neu zu trainieren, wird ein bereits existierendes Modell verwendet und weiter verfeinert, um es für bestimmte Anforderungen zu optimieren.